
Research Area: Software Testing
Software Testing for Web Applications:
When testing client-side web applications, it is important to consider different web-browser environments. Different properties of these environments such as web-browser types and underlying platforms may cause a web application to exhibit different types of failures. As web applications evolve, they must be regression tested across these different environments. Because there are many environments to consider this process can be expensive, resulting in delayed feedback about failures in applications. In this work, we propose six techniques for providing a developer with faster feedback on failures when regression testing web applications across different web-browser environments. Our techniques draw on methods used in test case prioritization; however, in our case we prioritize web-browser environments, based on information on recent and frequent failures.
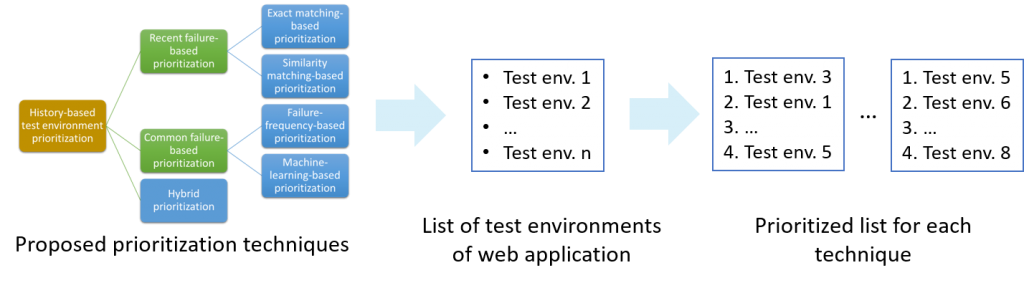 [Figure 1. Web environment prioritization]
[Figure 1. Web environment prioritization]
Software Defect Prediction & Technical debts:
We have worked with Samsung about software defect prediction and technical debts. We analyze data that can be extracted from software repositories, code reviews, and issue reports, and try to find prediction methods for software defects to outperform the existing defect prediction methods. In addition, we are working on technical debts to give useful information to developers and managers.
Web Service Data Augmentation for Software Testing:
Test data augmentation techniques generate new test data from existing test data, with the aim of finding new variants of existing test cases that utilize program inputs in different ways, exercising different program behaviors. Augmentation can increase the likelihood that a program under test works correctly, and can help engineers statistically estimate software reliability and verify fault corrections.
Issue Tracking-Based Test Data Augmentation for Web Services:
Our approach automatically analyzes URIs that have been used to reproduce faults reported in an issue tracking system, identifies relevant URIs, and creates new test data by augmenting existing test cases. The approach helps developers find new test cases related to an issue without running all test cases whenever an issue is reported. Additionally, our approach may help developers create new test cases that handle issues in advance. When a fault is revealed by test cases, developers can provide remedies at the client level such as exception handlers and bypass code until the issue is resolved by the service provider.
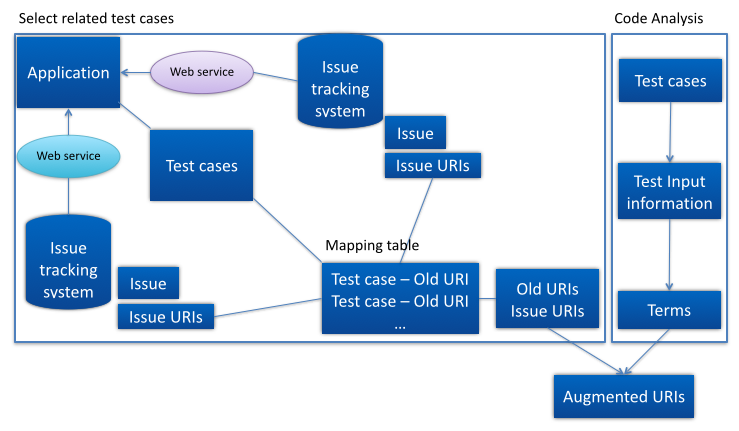
[Figure 2 Overall structure of test data augmentation process]
Test Case Prioritization:
In regression testing, existing test cases are executed to check whether the software still works correctly after modifications. Running all test cases is the simplest way to perform regression testing; however, this may require a great deal of time and computing resources. Existing regression testing methods such as test case selection, test case prioritization and test suite reduction attempt to make regression testing more cost-effective. The focus of this work is test case prioritization (TCP), which attempts to schedule test cases in order to achieve goals such as faster code coverage or higher rates of fault detection. TCP is typically required when there are many test cases but testing time is limited. Modern software development is characterized by frequent software updates, underlining the importance of TCP. Previous TCP techniques have focused largely on code coverage information such as line and branch coverage, since a test case having greater code coverage may naturally be expected to find more defects in the system under test. However, in some cases, code coverage is not a good predictor of the fault detection ability of a testing process. In such cases, code coverage-based techniques for prioritization may not be especially effective. Recent work has explored the use of other information along with the code coverage for prioritizing test cases. For example, there is research on utilizing software requirements or human assistance. However, there has been little research focusing on code rarely executed by existing test cases. Leon et al. point out the importance of considering the frequency at which code is tested. Examples of less tested code include exception handling code and code handling unusual conditions. Putting weight on test cases executing such code regions may increase the rate at which faults are detected.
Test Case Prioritization Based on Information Retrieval Concepts:
We propose an alternative prioritization technique that adapts Term Frequency (TF) and Inverted Document Frequency (IDF) to overcome the limitations of code coverage based prioritization techniques. TF and IDF are basic concepts in the Information Retrieval (IR) field. We believe that such an approach may find defects more quickly by considering not only code coverage information but also how many times a coverage element has been executed by a test case (TF) and source code elements tested by few test cases (IDF). Our approach adopts a linear regression model to automatically determine how to weigh the value of these two sources of information during prioritization. As in most TCP approaches, each test case is given a value and the test cases are scheduled according to the values.
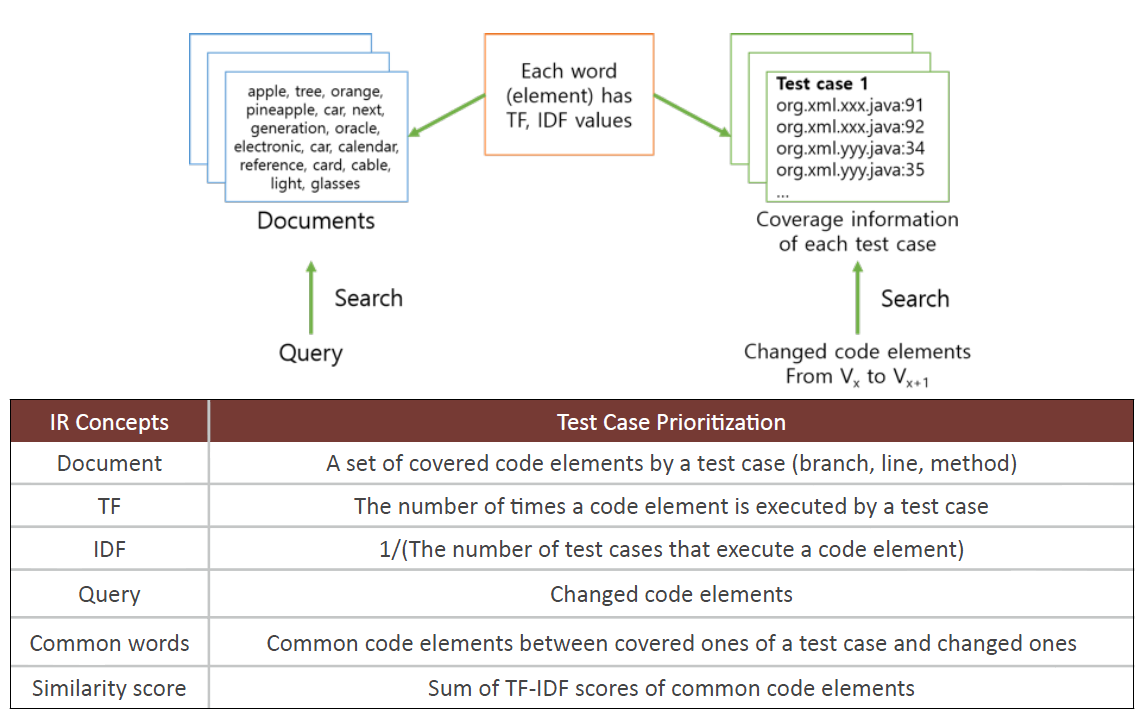
[Figure 3 Applying the IR concepts to Test Case Prioritization]